抓包工具fiddler使用实例—查找真实网址
ET采集器是根据页面源代码采集信息的,但我们经常遇到一些网页的内容在源代码里看不见,而在浏览器中能显示。
这种情况通常是网页中使用了脚本或框架来调用、加载真实网址的内容。比如常见的响应式、瀑布流列表网页、文章的评论部分,又或者是某些电商平台的商品信息。
如果是IFRAME框架,可以在源代码中简单的看到框架src属性里的真实网址,但脚本调用的就很难找到调用的真实网址了,这时候,最简单的办法是用抓包工具来找到这类网址。
我们推荐使用fiddler,一个很棒的免费抓包工具。
fiddler官方下载地址:http://www.telerik.com/download/fiddler
我们以新浪的滚动新闻举例
在访问这个新闻网址时,源代码里找不到我们看到的新闻标题和文章网址,我们要用fiddler去找下,这些标题和网址信息到底是包含在那个网页里的。
第一步 抓包
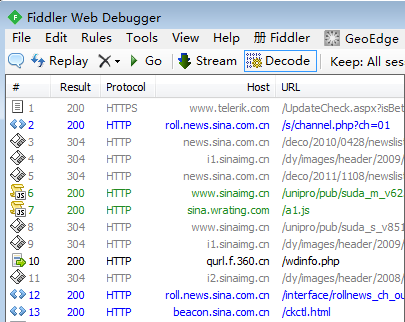
我们把fiddler软件打开,然后在浏览器里刷新一下这个新浪滚动新闻的网页,我们在fiddler的左侧看到出现了很多网址,其中就有新浪域名roll.news.sina.com.cn,见下图:
第二步 停止抓包
防止抓到很多无用的东西,见下图:
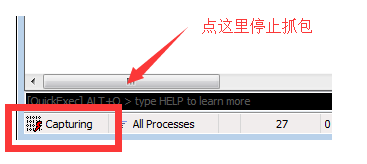
点击上图的位置就可以了,就是在fiddler左下角,点击下那个单词并消失,就停止抓包了,再点击此处空白处就会又出现,就会重新抓包。
第三步 查找页面真实网址
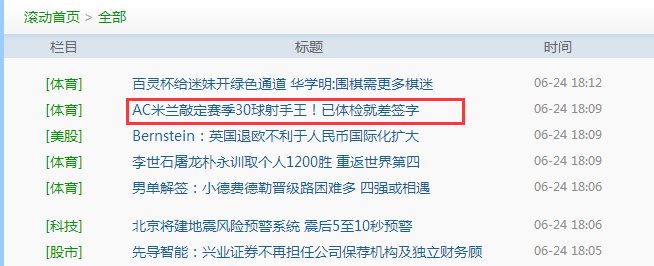
我们可以从浏览器上看到的标题、文章网址等信息中,选一项来查找,如我们从下图中选择一个标题,拷贝其中几个字。
按快捷键 ctrl+F 弹出查找的界面,输入 “AC米兰” (最好选择数字、字母关键词进行查找),如图:
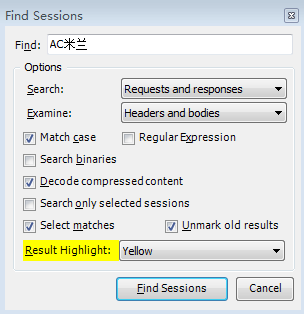
其中选项Decode compressed content 是用于压缩网页,建议勾选。
Result Highlight 是用什么颜色来高亮查找到的结果。
点击 Find Sessions,开始查找,结果如下图:
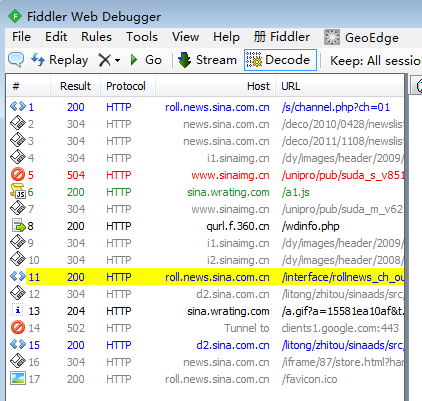
黄色高亮的这个网址就是我们找到的结果,鼠标单击它,然后看看右边的窗口,选择Inspectors页。
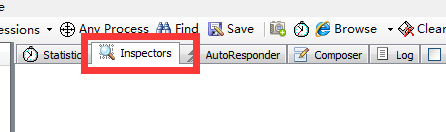
通过下方的各种标签页可以查看该网页的抓包信息,红框标注的是常用标签。
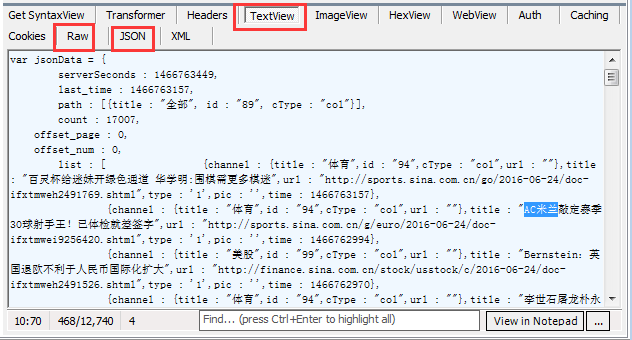
右边窗口展示了这个网址的抓包内容,我们可以选择 TextView、Raw来查看这个网址的内容,如果内容是JSON格式,还可以选择JSON。
这个网址的内容里包含了我们需要的标题、文章网址等信息,没错,它就是我们要找的真实新浪滚动新闻列表网址。
第四步 复制网址
对于GET类型的网址,可以直接在这个网址上点右键,选择copy - just Url ,或按快捷键 CTRL+ U 复制网址。
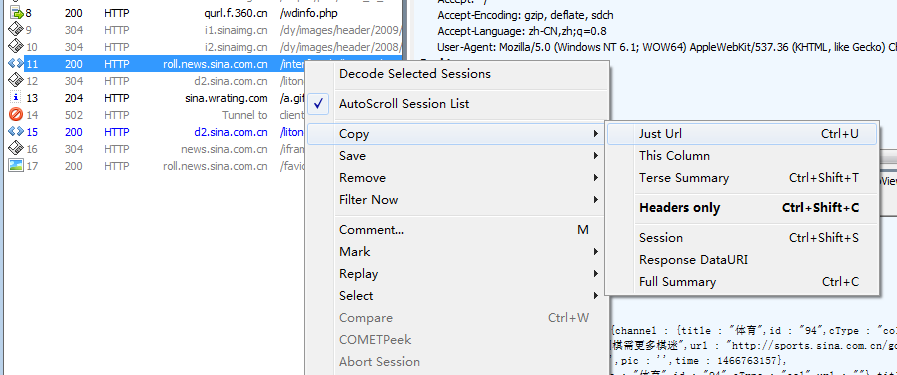
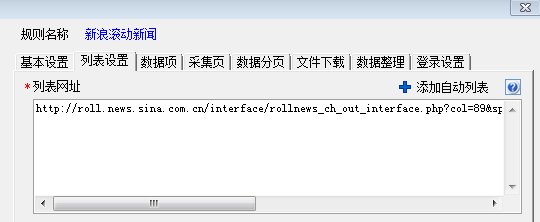
fiddler抓到的这个地址,就是滚动新闻列表页地址:http://roll.news.sina.com.cn/interface/rollnews_ch_out_interface.php?col=89&spec=&type=&ch=01&k=&offset_page=0&offset_num=0&num=60&asc=&page=1&r=0.34277781937271357
将它粘贴到ET采集的采集配置-列表网址中。
对于POST类型的网址,除了复制网址,还应复制参数,并将参数合并到网址中,格式如 http://www.123.php?aa=bb&cc=dd,并在采集配置-基本设置中勾选“启用POST请求优先模式”。
其他
使用fiddler,可以方便的获得网站的COOKIES和USERAGENT等信息,如图:
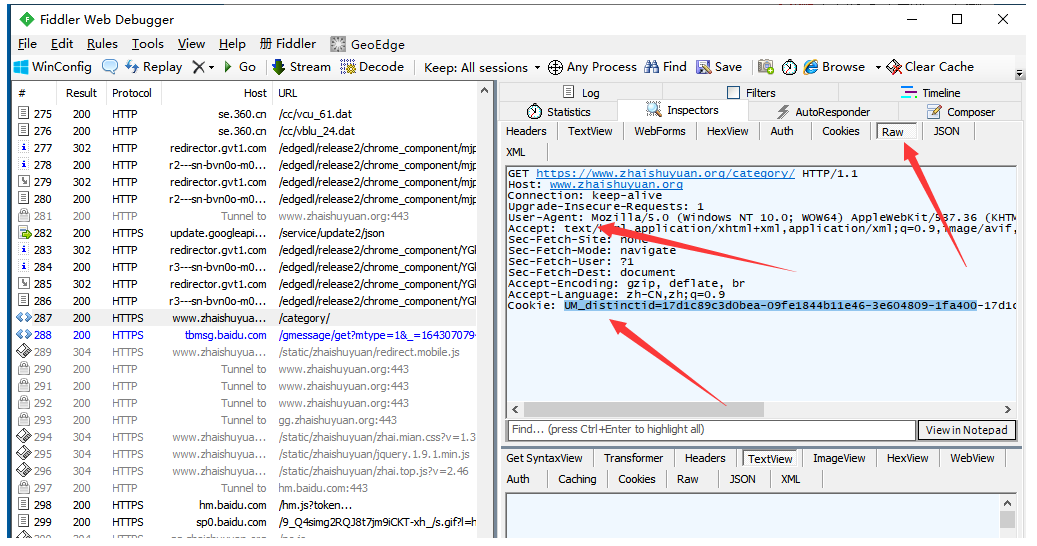
注:如果你的fildder不能正常显示中文,需要在注册表路径HKEY_CURRENT_USER\Software\Microsoft\Fiddler2中增加一个字符串键值,取值为GBK或gb2312
 川公网安备 51078102110085号
川公网安备 51078102110085号