基础实例-采集页的使用-XX小说采集案例
在采集XX小说文章时,我们发现,文章网页的源代码文件里找不到正文文字,它是用一个JS脚本文件显示的正文,如图1:

(图1)
访问这个js文件,可以看到其中包含了文章正文,如图2:
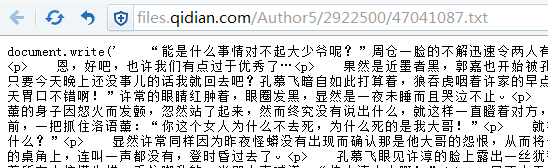
(图2)
在不同的网页,包含我们所要采集的不同数据,它的结构如图3:
(图3)
要采集这类网站,我们需要用到ET的采集页功能,如图4:
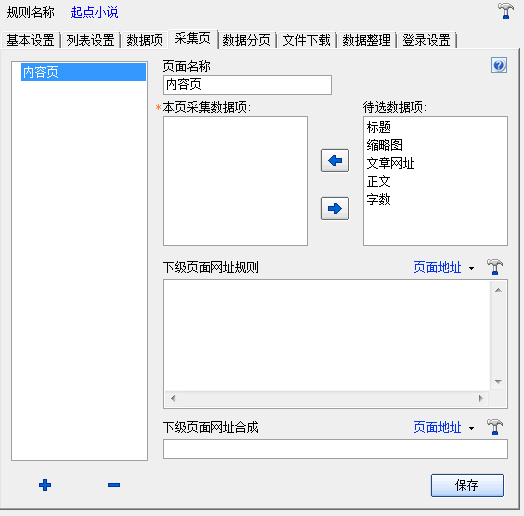
(图4)
图4里的内容页,即从列表页获取的文章网址指向的网页,对于多数网站,我们所要采集的数据都在这个页面里。
具体操作如下:
第一步,设置内容页的访问下级规则
内容页的下级页面,也就是我们包含我们要采集正文的脚本网页,这里的“下级页面网址规则”和“下级页面网址合成”就用于从内容页访问脚本网页,如图5:
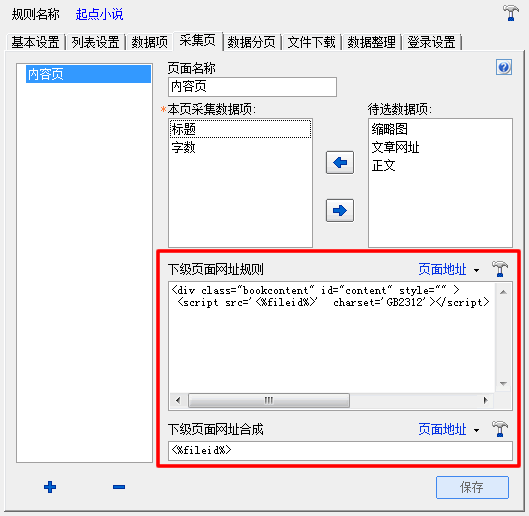
(图5)
设置这里时,请多用小榔头测试按钮确保采集的下级网址正确;并不要忘记,在“本页采集数据项”栏里选择要从本页采集的数据项;
第二步,新建采集页
点“+”号按钮,新建一个采集页,改名为“正文脚本页”,并保存,如图6:
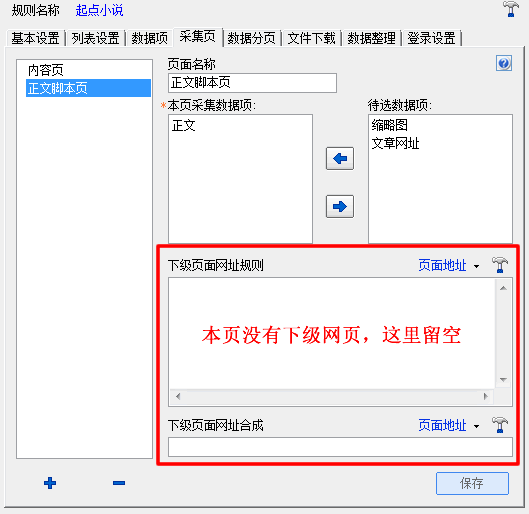
(图6)
因为正文脚本页没有下级网页了,所以不需要设置它的下级页面网址;同时,记得在“本页采集数据项”栏里选择“正文”数据项,告诉ET,从本页采集正文数据。
至此采集页配置已经完成,其他设置和采集普通网页完全一样;唯一注意,正文数据项是从“正文脚本页”里采集的,设置它的数据采集规则时不要弄错了目标网页了,如图7:
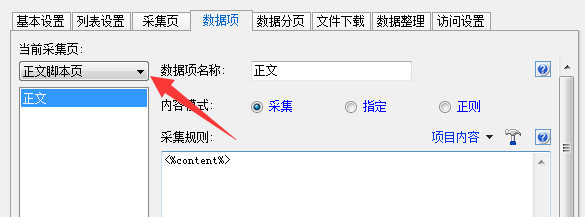
(图7)
用户在采集淘宝等使用脚本显示内容的网站,或者用iframe框架包含其他页面的网站,以及需要从页面中的链接访问其他网页采集信息的,都可以使用采集页功能。
 川公网安备 51078102110085号
川公网安备 51078102110085号